Comment récupérer des données et les streamer
Cette page vous guidera sur la manière de récupérer des données dans les Composants Serveur et Client, et comment streamer les composants qui dépendent de données.
Récupération de données
Composants Serveur
Vous pouvez récupérer des données dans les Composants Serveur en utilisant :
Avec l'API fetch
Pour récupérer des données avec l'API fetch, transformez votre composant en une fonction asynchrone et utilisez await sur l'appel à fetch. Par exemple :
export default async function Page() {
const data = await fetch('https://api.vercel.app/blog')
const posts = await data.json()
return (
<ul>
{posts.map((post) => (
<li key={post.id}>{post.title}</li>
))}
</ul>
)
}export default async function Page() {
const data = await fetch('https://api.vercel.app/blog')
const posts = await data.json()
return (
<ul>
{posts.map((post) => (
<li key={post.id}>{post.title}</li>
))}
</ul>
)
}Bon à savoir :
- Les réponses de
fetchne sont pas mises en cache par défaut. Cependant, Next.js prérendra la route et le résultat sera mis en cache pour améliorer les performances. Si vous souhaitez opter pour un rendu dynamique, utilisez l'option{ cache: 'no-store' }. Consultez la Référence API defetch.- Pendant le développement, vous pouvez enregistrer les appels
fetchpour une meilleure visibilité et un meilleur débogage. Consultez la référence API delogging.
Avec un ORM ou une base de données
Comme les Composants Serveur sont rendus côté serveur, vous pouvez interroger une base de données en toute sécurité à l'aide d'un ORM ou d'un client de base de données. Transformez votre composant en une fonction asynchrone et utilisez await sur l'appel :
import { db, posts } from '@/lib/db'
export default async function Page() {
const allPosts = await db.select().from(posts)
return (
<ul>
{allPosts.map((post) => (
<li key={post.id}>{post.title}</li>
))}
</ul>
)
}import { db, posts } from '@/lib/db'
export default async function Page() {
const allPosts = await db.select().from(posts)
return (
<ul>
{allPosts.map((post) => (
<li key={post.id}>{post.title}</li>
))}
</ul>
)
}Composants Client
Il existe deux manières de récupérer des données dans les Composants Client, en utilisant :
- Le hook
usede React - Une bibliothèque communautaire comme SWR ou React Query
Streamer des données avec le hook use
Vous pouvez utiliser le hook use de React pour streamer des données du serveur vers le client. Commencez par récupérer les données dans votre composant Serveur, puis passez la promesse à votre Composant Client comme prop :
import Posts from '@/app/ui/posts
import { Suspense } from 'react'
export default function Page() {
// Ne pas utiliser await sur la fonction de récupération de données
const posts = getPosts()
return (
<Suspense fallback={<div>Loading...</div>}>
<Posts posts={posts} />
</Suspense>
)
}import Posts from '@/app/ui/posts
import { Suspense } from 'react'
export default function Page() {
// Ne pas utiliser await sur la fonction de récupération de données
const posts = getPosts()
return (
<Suspense fallback={<div>Loading...</div>}>
<Posts posts={posts} />
</Suspense>
)
}Ensuite, dans votre Composant Client, utilisez le hook use pour lire la promesse :
'use client'
import { use } from 'react'
export default function Posts({
posts,
}: {
posts: Promise<{ id: string; title: string }[]>
}) {
const allPosts = use(posts)
return (
<ul>
{allPosts.map((post) => (
<li key={post.id}>{post.title}</li>
))}
</ul>
)
}'use client'
import { use } from 'react'
export default function Posts({ posts }) {
const posts = use(posts)
return (
<ul>
{posts.map((post) => (
<li key={post.id}>{post.title}</li>
))}
</ul>
)
}Dans l'exemple ci-dessus, le composant <Posts> est encapsulé dans une limite <Suspense>. Cela signifie que le fallback sera affiché pendant que la promesse est résolue. Apprenez-en plus sur le streaming.
Bibliothèques communautaires
Vous pouvez utiliser une bibliothèque communautaire comme SWR ou React Query pour récupérer des données dans les Composants Client. Ces bibliothèques ont leurs propres sémantiques pour la mise en cache, le streaming et d'autres fonctionnalités. Par exemple, avec SWR :
'use client'
import useSWR from 'swr'
const fetcher = (url) => fetch(url).then((r) => r.json())
export default function BlogPage() {
const { data, error, isLoading } = useSWR(
'https://api.vercel.app/blog',
fetcher
)
if (isLoading) return <div>Loading...</div>
if (error) return <div>Error: {error.message}</div>
return (
<ul>
{data.map((post: { id: string; title: string }) => (
<li key={post.id}>{post.title}</li>
))}
</ul>
)
}'use client'
import useSWR from 'swr'
const fetcher = (url) => fetch(url).then((r) => r.json())
export default function BlogPage() {
const { data, error, isLoading } = useSWR(
'https://api.vercel.app/blog',
fetcher
)
if (isLoading) return <div>Loading...</div>
if (error) return <div>Error: {error.message}</div>
return (
<ul>
{data.map((post) => (
<li key={post.id}>{post.title}</li>
))}
</ul>
)
}Déduplication des requêtes avec React.cache
La déduplication est le processus qui consiste à éviter les requêtes en double pour la même ressource pendant un rendu. Cela vous permet de récupérer les mêmes données dans différents composants tout en évitant plusieurs requêtes réseau vers votre source de données.
Si vous utilisez fetch, les requêtes peuvent être dédupliquées en ajoutant cache: 'force-cache'. Cela signifie que vous pouvez appeler la même URL avec les mêmes options en toute sécurité, et une seule requête sera effectuée.
Si vous n'utilisez pas fetch, mais plutôt un ORM ou une base de données directement, vous pouvez encapsuler votre récupération de données avec la fonction React cache.
import { cache } from 'react'
import { db, posts, eq } from '@/lib/db'
export const getPost = cache(async (id: string) => {
const post = await db.query.posts.findFirst({
where: eq(posts.id, parseInt(id)),
})
})import { cache } from 'react'
import { db, posts, eq } from '@/lib/db'
import { notFound } from 'next/navigation'
export const getPost = cache(async (id) => {
const post = await db.query.posts.findFirst({
where: eq(posts.id, parseInt(id)),
})
})Streaming
Avertissement : Le contenu ci-dessous suppose que l'option de configuration
dynamicIOest activée dans votre application. Ce flag a été introduit dans Next.js 15 canary.
Lorsque vous utilisez async/await dans les Composants Serveur, Next.js optera pour un rendu dynamique. Cela signifie que les données seront récupérées et rendues côté serveur pour chaque requête utilisateur. S'il y a des requêtes de données lentes, toute la route sera bloquée pour le rendu.
Pour améliorer le temps de chargement initial et l'expérience utilisateur, vous pouvez utiliser le streaming pour diviser le HTML de la page en petits morceaux et les envoyer progressivement du serveur vers le client.
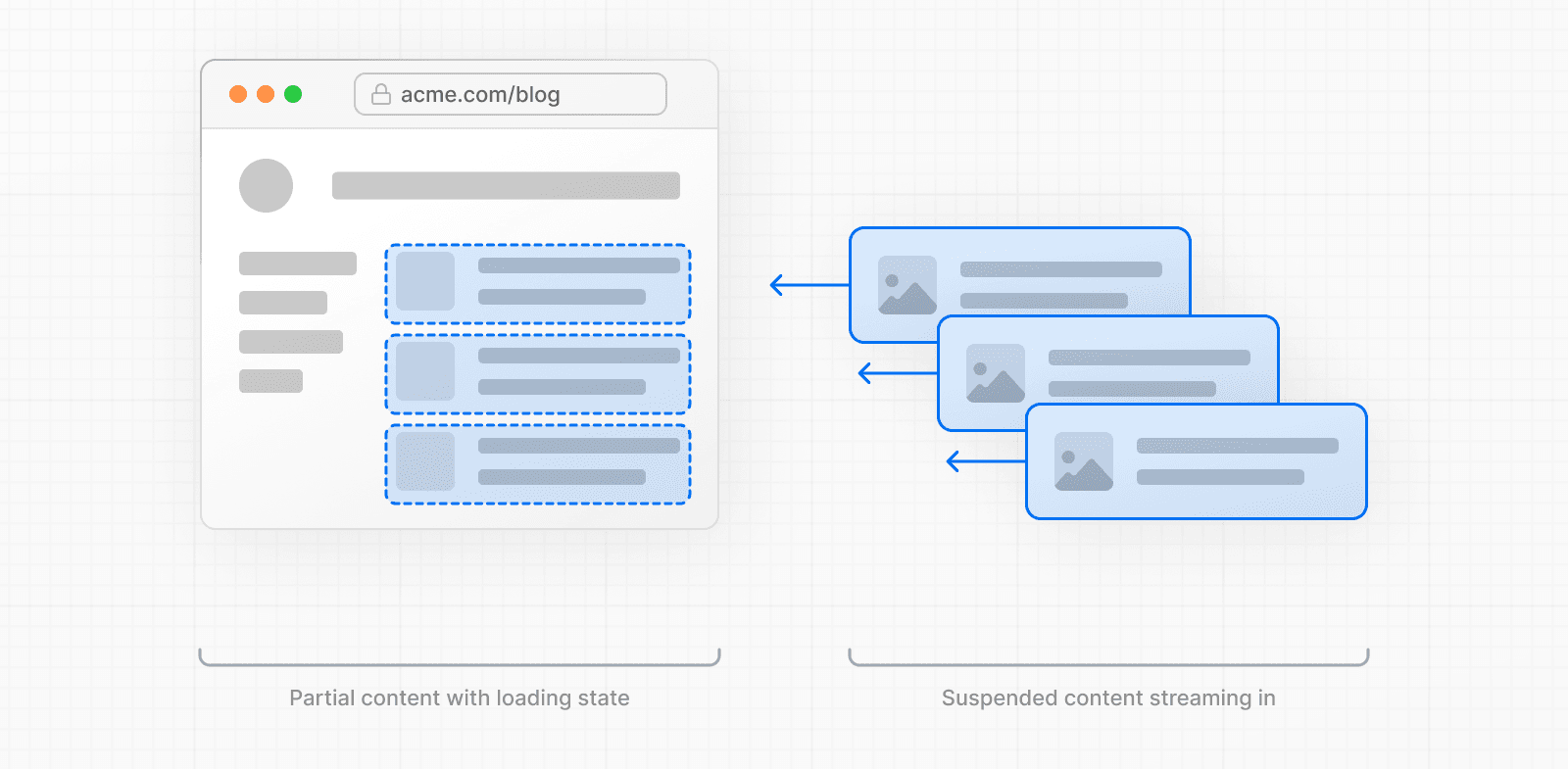
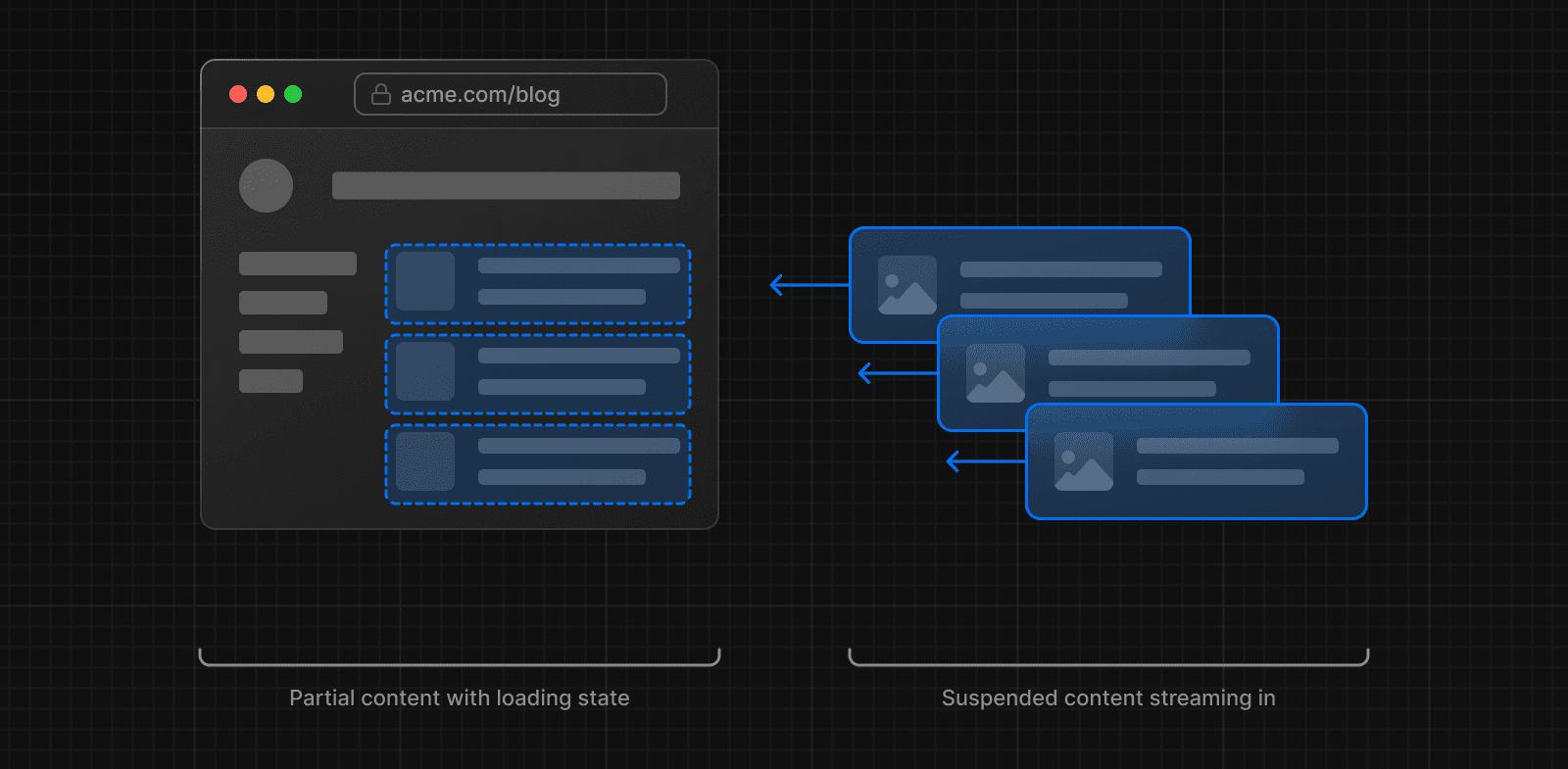
Il existe deux manières d'implémenter le streaming dans votre application :
- En encapsulant une page avec un fichier
loading.js - En encapsulant un composant avec
<Suspense>
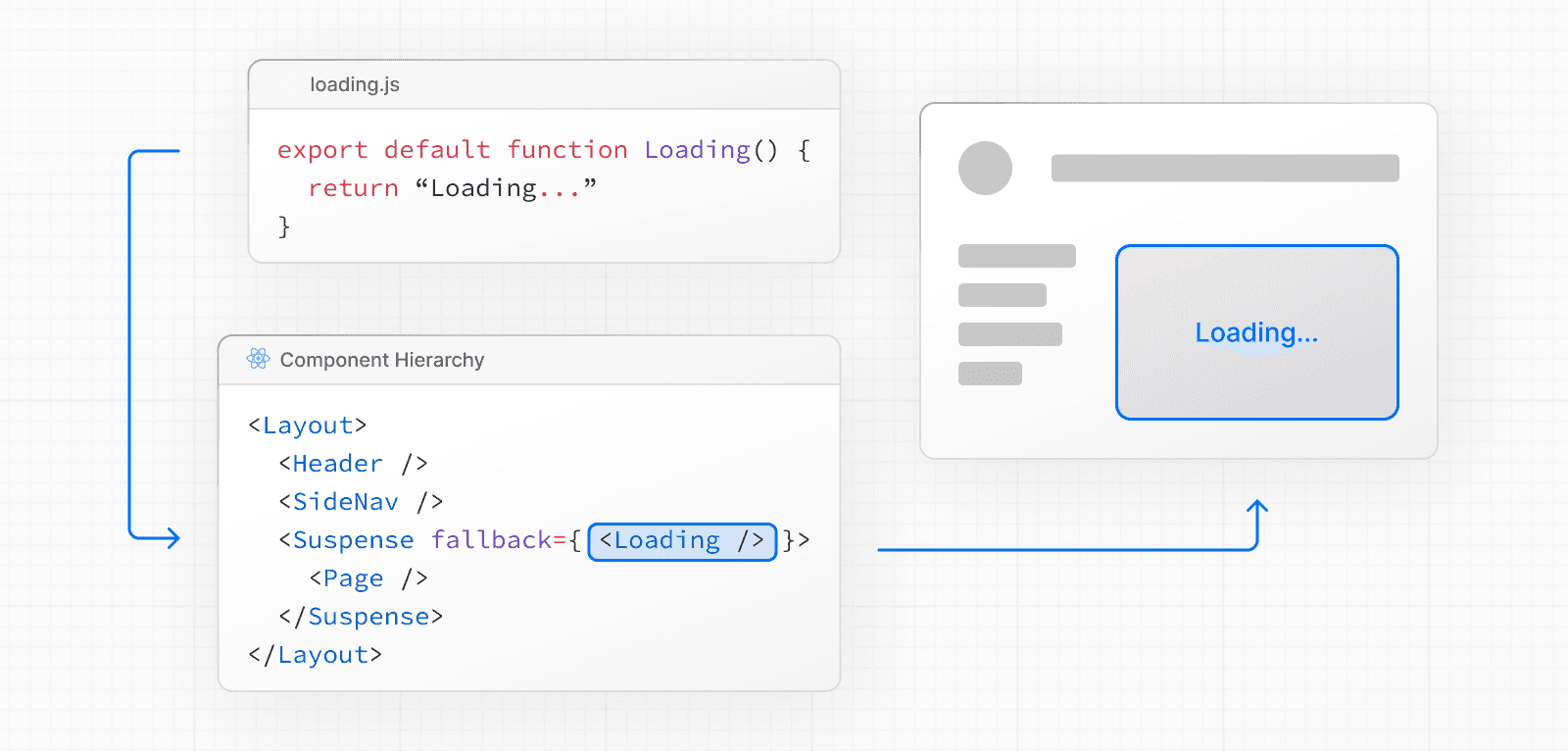
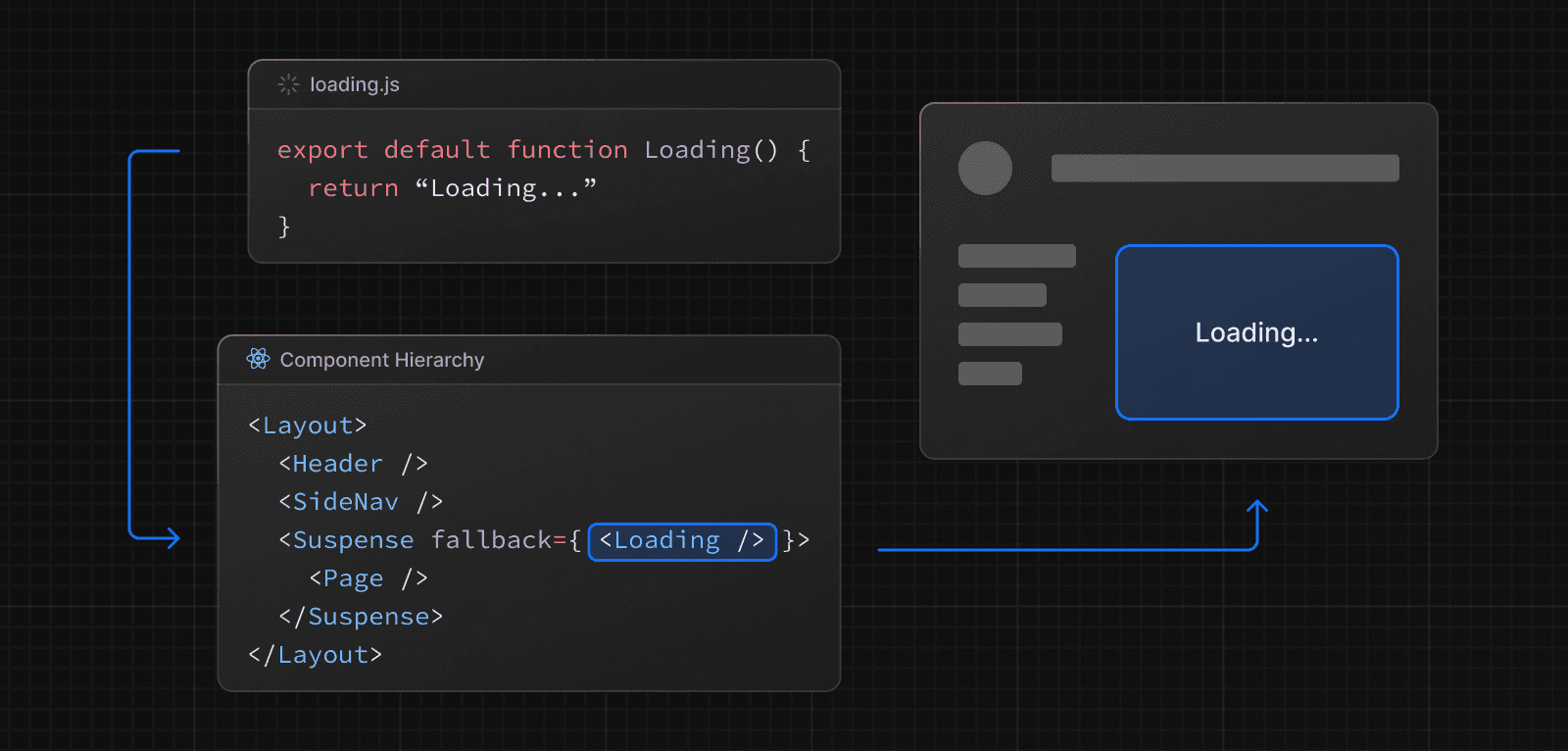
Avec loading.js
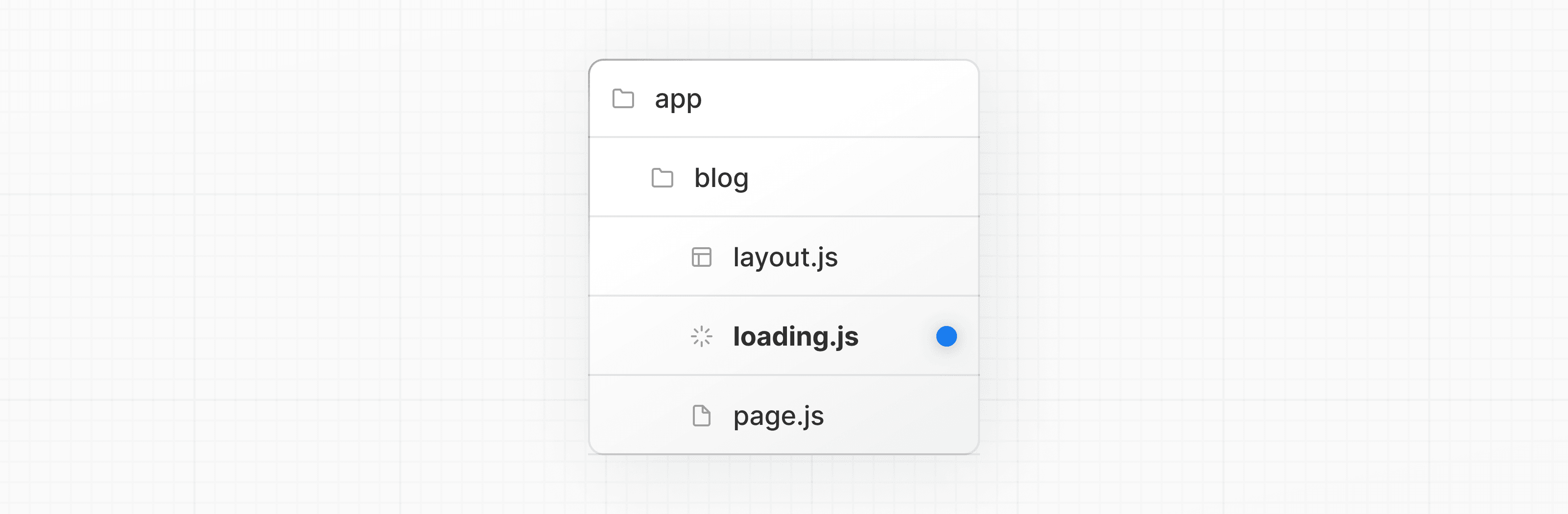
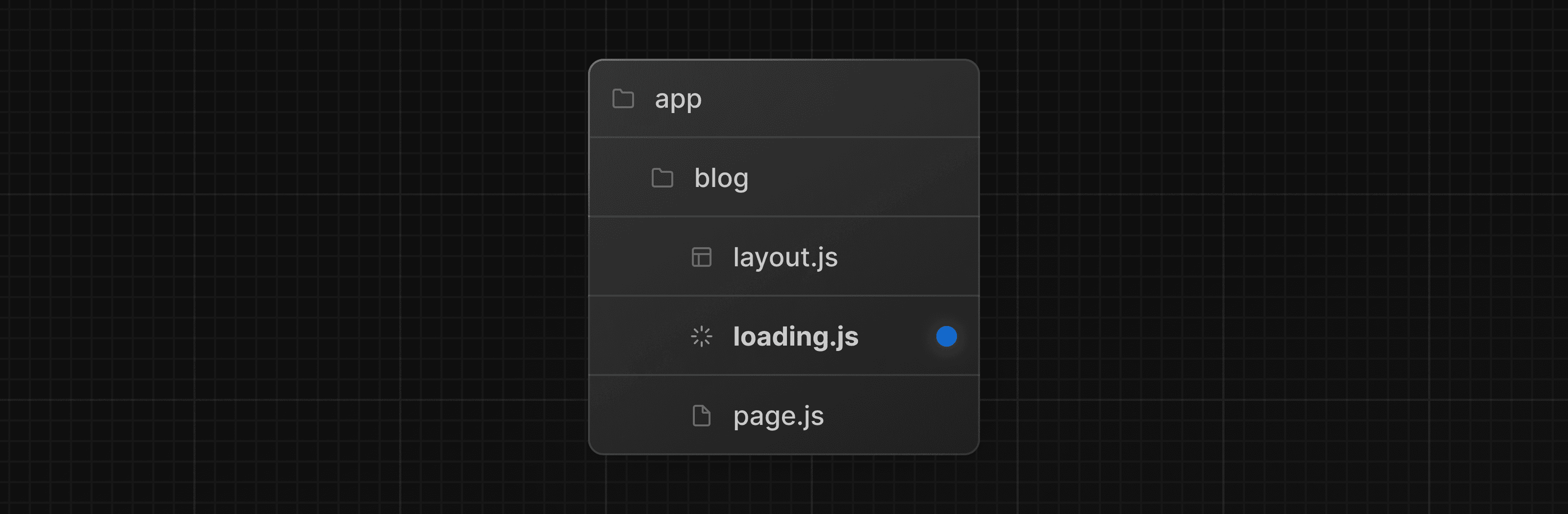
Vous pouvez créer un fichier loading.js dans le même dossier que votre page pour streamer toute la page pendant que les données sont récupérées. Par exemple, pour streamer app/blog/page.js, ajoutez le fichier dans le dossier app/blog.
export default function Loading() {
// Définissez l'interface de chargement ici
return <div>Loading...</div>
}export default function Loading() {
// Définissez l'interface de chargement ici
return <div>Loading...</div>
}Lors de la navigation, l'utilisateur verra immédiatement la mise en page et un état de chargement pendant que la page est en cours de rendu. Le nouveau contenu sera automatiquement remplacé une fois le rendu terminé.
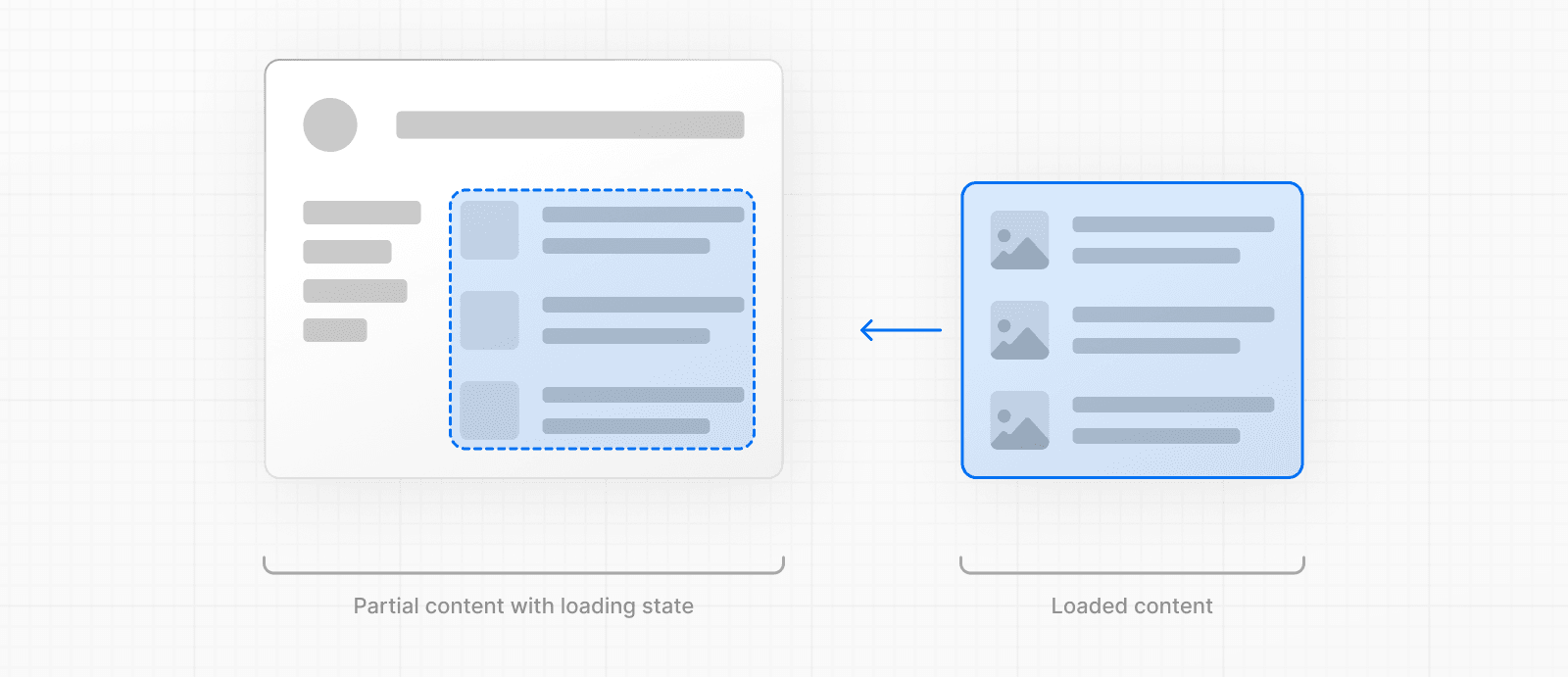
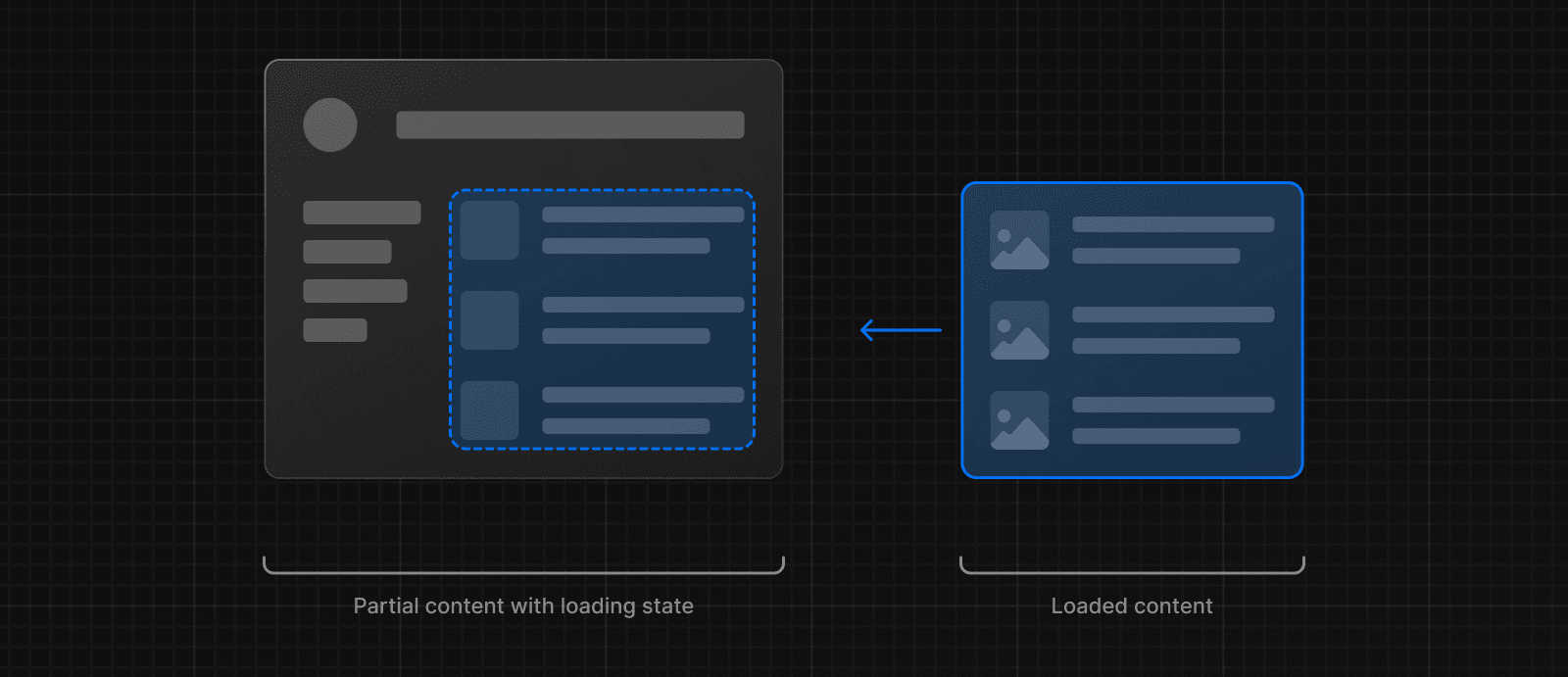
En arrière-plan, loading.js sera imbriqué dans layout.js et encapsulera automatiquement le fichier page.js et tous les enfants en dessous dans une limite <Suspense>.
Cette approche fonctionne bien pour les segments de route (layouts et pages), mais pour un streaming plus granulaire, vous pouvez utiliser <Suspense>.
Avec <Suspense>
<Suspense> vous permet d'être plus précis sur les parties de la page à streamer. Par exemple, vous pouvez afficher immédiatement tout contenu de page qui se trouve en dehors de la limite <Suspense>, et streamer la liste des articles de blog à l'intérieur de la limite.
import { Suspense } from 'react'
import BlogList from '@/components/BlogList'
import BlogListSkeleton from '@/components/BlogListSkeleton'
export default function BlogPage() {
return (
<div>
{/* Ce contenu sera envoyé au client immédiatement */}
<header>
<h1>Bienvenue sur le Blog</h1>
<p>Lisez les derniers articles ci-dessous.</p>
</header>
<main>
{/* Tout contenu encapsulé dans une limite <Suspense> sera streamé */}
<Suspense fallback={<BlogListSkeleton />}>
<BlogList />
</Suspense>
</main>
</div>
)
}import { Suspense } from 'react'
import BlogList from '@/components/BlogList'
import BlogListSkeleton from '@/components/BlogListSkeleton'
export default function BlogPage() {
return (
<div>
{/* Ce contenu sera envoyé au client immédiatement */}
<header>
<h1>Bienvenue sur le Blog</h1>
<p>Lisez les derniers articles ci-dessous.</p>
</header>
<main>
{/* Tout contenu encapsulé dans une limite <Suspense> sera streamé */}
<Suspense fallback={<BlogListSkeleton />}>
<BlogList />
</Suspense>
</main>
</div>
)
}Création d'états de chargement significatifs
Un état de chargement instantané est une interface utilisateur de fallback qui est affichée immédiatement à l'utilisateur après la navigation. Pour la meilleure expérience utilisateur, nous recommandons de concevoir des états de chargement significatifs qui aident les utilisateurs à comprendre que l'application répond. Par exemple, vous pouvez utiliser des squelettes et des spinners, ou une petite partie significative des écrans futurs comme une photo de couverture, un titre, etc.
En développement, vous pouvez prévisualiser et inspecter l'état de chargement de vos composants en utilisant les React Devtools.
Exemples
Récupération séquentielle de données
La récupération séquentielle de données se produit lorsque des composants imbriqués dans un arbre récupèrent chacun leurs propres données et que les requêtes ne sont pas dédupliquées, ce qui entraîne des temps de réponse plus longs.
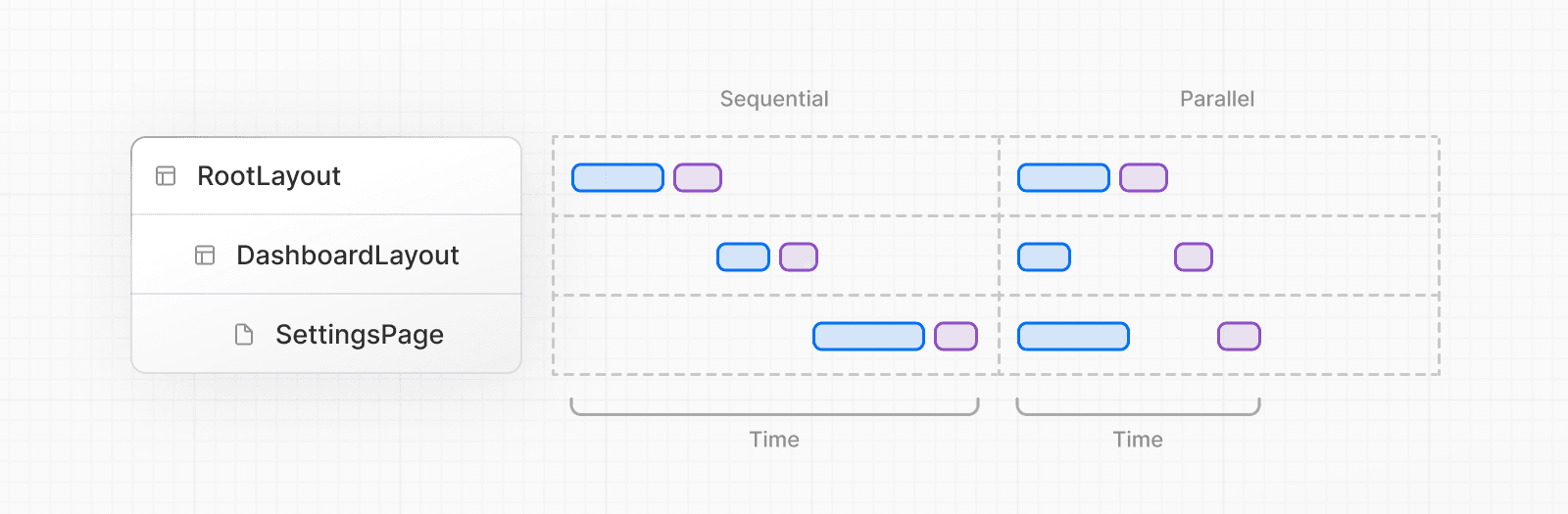
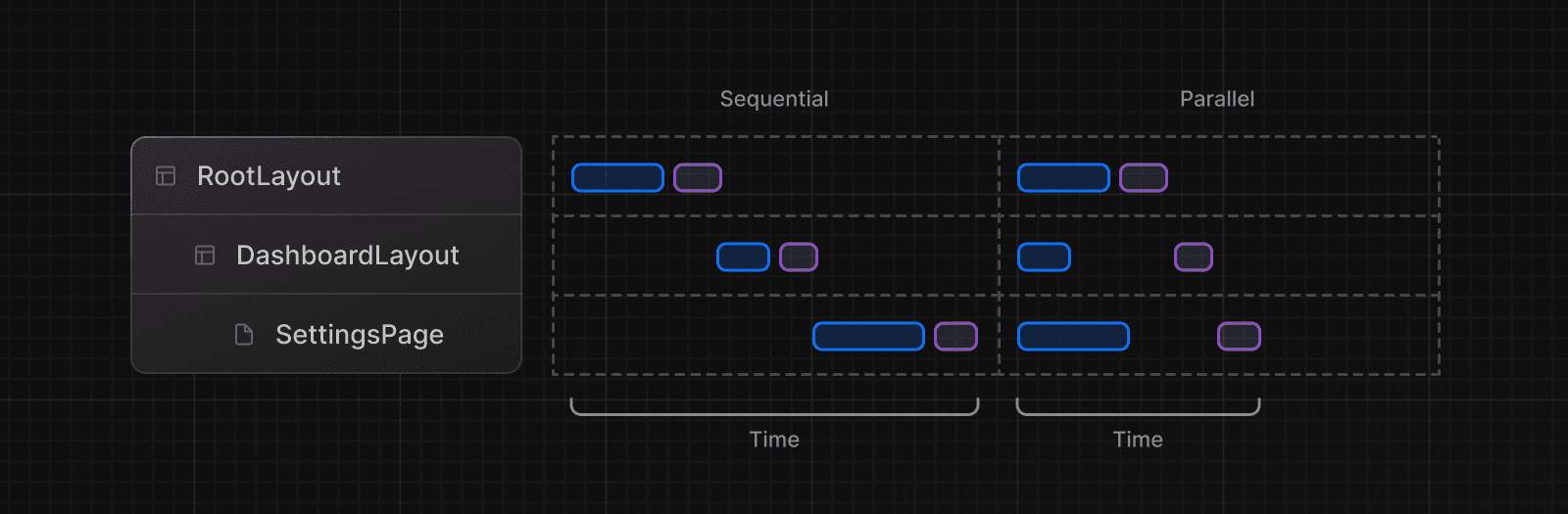
Il peut y avoir des cas où vous voulez ce modèle parce qu'une récupération dépend du résultat de l'autre.
Par exemple, le composant <Playlists> ne commencera à récupérer des données que lorsque le composant <Artist> aura terminé de récupérer ses données, car <Playlists> dépend de la prop artistID :
export default async function Page({
params,
}: {
params: Promise<{ username: string }>
}) {
const { username } = await params
// Récupérer les informations de l'artiste
const artist = await getArtist(username)
return (
<>
<h1>{artist.name}</h1>
{/* Afficher une interface de fallback pendant le chargement du composant Playlists */}
<Suspense fallback={<div>Loading...</div>}>
{/* Passer l'ID de l'artiste au composant Playlists */}
<Playlists artistID={artist.id} />
</Suspense>
</>
)
}
async function Playlists({ artistID }: { artistID: string }) {
// Utiliser l'ID de l'artiste pour récupérer les playlists
const playlists = await getArtistPlaylists(artistID)
return (
<ul>
{playlists.map((playlist) => (
<li key={playlist.id}>{playlist.name}</li>
))}
</ul>
)
}export default async function Page({ params }) {
const { username } = await params
// Récupérer les informations de l'artiste
const artist = await getArtist(username)
return (
<>
<h1>{artist.name}</h1>
{/* Afficher une interface de fallback pendant le chargement du composant Playlists */}
<Suspense fallback={<div>Loading...</div>}>
{/* Passer l'ID de l'artiste au composant Playlists */}
<Playlists artistID={artist.id} />
</Suspense>
</>
)
}
async function Playlists({ artistID }) {
// Utiliser l'ID de l'artiste pour récupérer les playlists
const playlists = await getArtistPlaylists(artistID)
return (
<ul>
{playlists.map((playlist) => (
<li key={playlist.id}>{playlist.name}</li>
))}
</ul>
)
}Pour améliorer l'expérience utilisateur, vous devez utiliser React <Suspense> pour afficher un fallback pendant que les données sont récupérées. Cela permettra le streaming et empêchera que toute la route soit bloquée par les requêtes de données séquentielles.
Récupération parallèle de données (Parallel data fetching)
La récupération parallèle de données se produit lorsque les requêtes de données dans une route sont initiées de manière anticipée et démarrent en même temps.
Par défaut, les layouts et pages sont rendus en parallèle. Ainsi, chaque segment commence à récupérer les données dès que possible.
Cependant, dans n'importe quel composant, plusieurs requêtes async/await peuvent toujours être séquentielles si elles sont placées les unes après les autres. Par exemple, getAlbums sera bloqué jusqu'à ce que getArtist soit résolu :
import { getArtist, getAlbums } from '@/app/lib/data'
export default async function Page({ params }) {
// Ces requêtes seront séquentielles
const { username } = await params
const artist = await getArtist(username)
const albums = await getAlbums(username)
return <div>{artist.name}</div>
}Vous pouvez initier les requêtes en parallèle en les définissant en dehors des composants qui utilisent les données, et en les résolvant ensemble, par exemple avec Promise.all :
import Albums from './albums'
async function getArtist(username: string) {
const res = await fetch(`https://api.example.com/artist/${username}`)
return res.json()
}
async function getAlbums(username: string) {
const res = await fetch(`https://api.example.com/artist/${username}/albums`)
return res.json()
}
export default async function Page({
params,
}: {
params: Promise<{ username: string }>
}) {
const { username } = await params
const artistData = getArtist(username)
const albumsData = getAlbums(username)
// Initie les deux requêtes en parallèle
const [artist, albums] = await Promise.all([artistData, albumsData])
return (
<>
<h1>{artist.name}</h1>
<Albums list={albums} />
</>
)
}import Albums from './albums'
async function getArtist(username) {
const res = await fetch(`https://api.example.com/artist/${username}`)
return res.json()
}
async function getAlbums(username) {
const res = await fetch(`https://api.example.com/artist/${username}/albums`)
return res.json()
}
export default async function Page({ params }) {
const { username } = await params
const artistData = getArtist(username)
const albumsData = getAlbums(username)
// Initie les deux requêtes en parallèle
const [artist, albums] = await Promise.all([artistData, albumsData])
return (
<>
<h1>{artist.name}</h1>
<Albums list={albums} />
</>
)
}Bon à savoir : Si une requête échoue lors de l'utilisation de
Promise.all, l'opération entière échouera. Pour gérer cela, vous pouvez utiliser la méthodePromise.allSettledà la place.
Préchargement des données (Preloading data)
Vous pouvez précharger les données en créant une fonction utilitaire que vous appelez de manière anticipée avant les requêtes bloquantes. <Item> s'affiche conditionnellement en fonction de la fonction checkIsAvailable().
Vous pouvez appeler preload() avant checkIsAvailable() pour initier de manière anticipée les dépendances de données de <Item/>. Au moment où <Item/> est rendu, ses données ont déjà été récupérées.
import { getItem } from '@/lib/data'
export default async function Page({
params,
}: {
params: Promise<{ id: string }>
}) {
const { id } = await params
// commence le chargement des données de l'élément
preload(id)
// effectue une autre tâche asynchrone
const isAvailable = await checkIsAvailable()
return isAvailable ? <Item id={id} /> : null
}
export const preload = (id: string) => {
// void évalue l'expression donnée et retourne undefined
// https://developer.mozilla.org/docs/Web/JavaScript/Reference/Operators/void
void getItem(id)
}
export async function Item({ id }: { id: string }) {
const result = await getItem(id)
// ...
}import { getItem } from '@/lib/data'
export default async function Page({ params }) {
const { id } = await params
// commence le chargement des données de l'élément
preload(id)
// effectue une autre tâche asynchrone
const isAvailable = await checkIsAvailable()
return isAvailable ? <Item id={id} /> : null
}
export const preload = (id) => {
// void évalue l'expression donnée et retourne undefined
// https://developer.mozilla.org/docs/Web/JavaScript/Reference/Operators/void
void getItem(id)
}
export async function Item({ id }) {
const result = await getItem(id)
// ...De plus, vous pouvez utiliser la fonction cache de React et le package server-only pour créer une fonction utilitaire réutilisable. Cette approche vous permet de mettre en cache la fonction de récupération de données et de vous assurer qu'elle n'est exécutée que sur le serveur.
import { cache } from 'react'
import 'server-only'
import { getItem } from '@/lib/data'
export const preload = (id: string) => {
void getItem(id)
}
export const getItem = cache(async (id: string) => {
// ...
})import { cache } from 'react'
import 'server-only'
import { getItem } from '@/lib/data'
export const preload = (id) => {
void getItem(id)
}
export const getItem = cache(async (id) => {
// ...
})